
Autonomous AI agents went from demo to production in barely a year, and security never caught up. These systems don’t just answer questions — they call tools, move money, read inboxes, and execute code on your behalf, which turns every prompt into a potential command. The scale of the problem is already measurable: in Gravitee’s State of AI Agent Security 2026, 88% of organizations running agents reported a confirmed or suspected security incident in the past year. AI agent security is no longer a research topic — it’s an operational gap. The fix isn’t to slow down; it’s to put a secure control plane in front of every model and tool call, which is exactly what an AI gateway like OrcaRouter is built to provide.
Quick take: The biggest agentic risks aren’t exotic — they’re prompt injection, excessive agency, and data leakage. The teams that stay safe don’t trust the agent; they constrain it at the boundary with input filtering, least-privilege tool access, PII redaction, and full request logging. Treat the agent as untrusted by default.
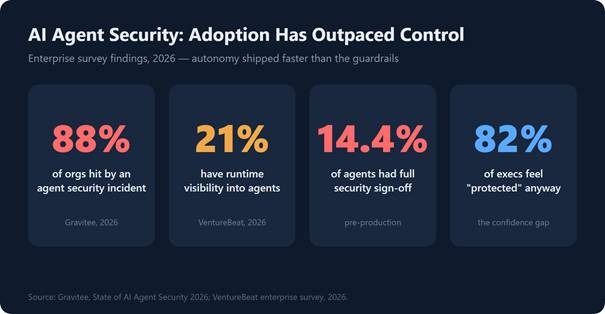
Adoption has badly outpaced control. Sources: Gravitee and VentureBeat, 2026.
Why agents are a new attack surface
A chatbot that only outputs text is low-risk. An agent is different: it has memory, autonomy, and a toolbelt. When you let a model decide which tool to invoke and with what arguments, you hand control flow to a system that can be steered by whatever text lands in its context window — a web page, an email, a calendar invite, a returned API payload. That’s why the OWASP Top 10 for Agentic Applications 2026, published in December 2025 by 100+ practitioners, reframed the threat model around autonomy rather than the model itself.
The visibility gap makes it worse. Per the same surveys, only 21% of organizations have runtime visibility into what their agents actually do, and only 14.4% of agents reached production with full security and IT approval. Meanwhile 82% of executives feel confident their existing policies cover agent actions — a confidence the 88% incident rate flatly contradicts.
The top AI agent security risks
| Risk | What it means | Why it’s dangerous |
| Prompt injection | Malicious text in the agent’s context overrides its instructions | Still the #1 cause of production failures |
| Excessive agency | Agent has broader permissions/tools than the task needs | Most consistently reported failure across surveys |
| Tool misuse & privilege escalation | Agent uses legitimate tools in unintended, unsafe ways | One of the highest-volume incident categories |
| Sensitive data leakage | PII or secrets flow into prompts, logs, or third-party models | Often silent until a breach disclosure |
| Memory poisoning | Attacker corrupts the agent’s persistent memory/RAG store | Persists across sessions; hard to detect |
1. Prompt injection is the dominant threat
Prompt injection remains the single largest driver of agentic security failures in production. Indirect injection is the scary variant: the payload hides in data the agent reads, not in what the user types. In a January 2026 experiment documented in OWASP’s GenAI exploit round-up, a single poisoned email fed to a RAG agent led to successful SSH-key exfiltration roughly 80% of the time — no user action required.
2. Excessive agency and tool misuse
The most common real-world failure is mundane: agents are simply over-permissioned. A support agent that can also delete records, send wire transfers, or hit internal admin APIs is one clever prompt away from doing exactly that. Lumenova’s analysis of the OWASP/NIST guidance puts excessive agency and tool misuse near the top of confirmed incidents because they require no novel exploit — just scope the model never should have had.
3. Data leakage to third-party models
Every agent call potentially ships your data to an external provider. Without redaction at the boundary, PII, API keys, and proprietary code end up in prompts and provider-side logs you don’t control.
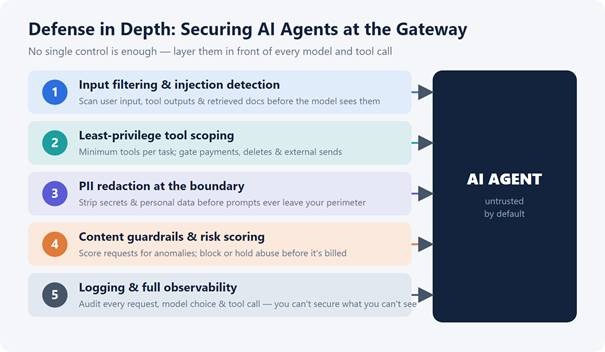
Defense in depth: no single control is enough — layer them at the gateway.
How to secure AI agents
You can’t make a model immune to manipulation, so you constrain what a manipulated model is allowed to do. Five layers, ideally enforced at a single gateway in front of every call:
1. Treat all input as untrusted. Filter and scan inputs (including tool outputs and retrieved documents) for injection patterns before they reach the model.
2. Enforce least privilege. Give each agent the minimum tools and scopes for its job; gate high-impact actions (payments, deletes, external sends) behind explicit approval.
3. Redact sensitive data at the boundary. Strip PII and secrets before prompts leave your perimeter — not after.
4. Apply guardrails and risk scoring. Score requests for anomalies and block or hold ones that look like abuse, ideally before they’re billed.
5. Log everything. Capture every request, model choice, tool call, and latency so you can audit, alert, and roll back. You can’t secure what you can’t see.
This is precisely the model-agnostic control plane an AI gateway gives you: one enforcement point for filtering, PII redaction, guardrails, role-based access, and observability across every provider — so security doesn’t have to be re-implemented per agent or per model.
The bottom line
AI agent security in 2026 is a governance problem, not a model problem. The headline numbers — 88% breached, 21% with visibility, 14.4% approved — describe organizations that shipped autonomy faster than control. The defense is unglamorous and effective: assume the agent is compromised, constrain its blast radius with least privilege, redact data at the edge, and log every action. Put those controls at a gateway and you get them once, everywhere, instead of bolting them onto each agent after the next incident.
Frequently asked questions
What is AI agent security? It’s the practice of protecting autonomous AI systems — which call tools and take actions — from manipulation, misuse, and data exposure. It focuses on constraining what an agent can do, not just what it says.
What is the biggest AI agent security risk? Prompt injection, especially indirect injection where malicious instructions hide in data the agent reads.
What is the OWASP Top 10 for Agentic Applications? A 2026 risk classification covering the critical threats to autonomous agents, including prompt injection, excessive agency, tool misuse, and memory poisoning.
How do I stop prompt injection? You can’t fully prevent it, so layer defenses: input filtering, least-privilege tool access, output validation, human approval for high-impact actions, and full logging.
Why is excessive agency dangerous? Because over-permissioned agents can be steered into harmful actions with no novel exploit — the access alone is the vulnerability.